Out-Of-Core Point Cloud Support
The Visualize OOC sprocket is an out-of-core system that processes and renders large amounts of data. This system is designed take as its input a collection of points. Points can be provided in two ways: either from memory, or from the following point cloud file formats: .ptx, .xyz, or .pts. In a multi-stage process, OOC transforms the raw point cloud data into a compressed format and renders it with high visual quality without sacrificing performance.
To begin, a preprocessor loads raw input data and restructures and compresses the data. The preprocessor creates an OOC file, a special-purpose HSF file, as well as a directory of data node files. This processed data can be as small as a third of the size of the original raw input. The resultant OOC file can be loaded and rendered in the HOOPS graphics system.

The OOC Sprocket Workflow.
OOC provides a simple command-line executable called ooc.exe for processing your data when loaded from a file. It is available for Windows and can be found in the tools/ooc directory of the Visualize package. Running ooc.exe without arguments will display help information.
When the preprocessor receives a point cloud file, it performs three passes of the data. In each pass, every single data point is examined. As a result, this stage can take a significant amount of time. We suggest that you allow for sufficient preprocessing time prior to loading and rendering your model.
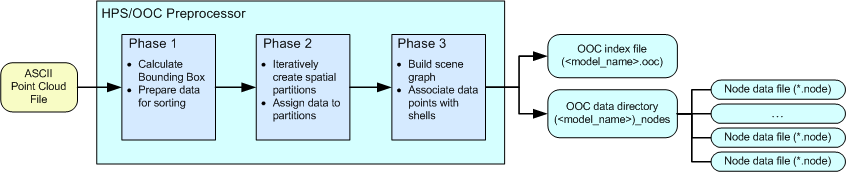
The three phases of preprocessing
Preprocessing Data
The following list describes the three phases of input data preprocessing:
OOC loads in all the data points and calculates a bounding box that contains the entire data set. One or more temporary binary file(s) are created to house the data for rapid access in subsequent phases.
OOC reads the temporary binary file(s) and then spatially sorts the points. If a user-specified bounding box was defined, OOC will exclude any points outside of this volume. Additionally, users can specify a subsample percentage that tells OOC to sort only a portion of the points in the dataset.
OOC uses a version of the binary space partition algorithm to sort the data. For each partition, it creates a node that stores a user-specifiable number of points. This number will be the size of the shell that later is loaded into the HOOPS database. If the number of data points exceeds the limit, then OOC subdivides the node further until the threshold is not surpassed.
While sorting the points, OOC adheres to a memory limit. If the memory usage reaches the limit, OOC writes the least recently used nodes out to disk to free up memory so that it can continue processing the remaining data.
After the data has been spatially sorted, OOC organizes the points into an appropriate scene graph so that HOOPS can render the data efficiently. Beginning at the root node, OOC creates a shell and assigns a randomized user-specified number of points to it. As OOC moves down the tree, the child nodes are representations of the partitions created in phase two. Each child node is populated with a percentage of the data corresponding to the fraction of data that resides in its respective partitioned area. OOC moves recursively until the leaves of the tree are reached and there are no more partitions. This tree structure is written to an OOC file (<filename>.ooc) while the data that belongs to each node is written into a node file (.node). Node files live in a directory with the same root name and at the same level as the OOC file.
Using the ooc.exe Preprocessor
To preprocess a point cloud file, run ooc.exe from the command line. ooc.exe is available on Windows. This program takes a number of options - but the most important is the input filename, which is passed with the -f option. The following example shows how you might preprocess the MyPointCloud.ptx ASCII point cloud file: :
> ooc.exe -f ../data/MyPointCloud.ptx -l ../data/MyPointCloudLog.txt
The above command line entry tells ooc.exe to process the ../data/MyPointCloud.ptx file. In the data directory, it creates a MyPointCloudLog_ptx.ooc file along with a MyPointCloudLog_ptx_nodes directory that contains a series of .node data files. Additionally, it will also create a MyPointCloudLog.txt log file. The preprocessor takes a number of options that lets you control how your data is analyzed and organized. They are as follows:
Input filename: use -f to specify the name and path of the ASCII point cloud file. To specify multiple input files, provide multiple ‘-f filename’ arguments to the preprocessor or give a ‘-F filename’ with a file containing a list of point cloud files (one per line).
Output filename: use -o to specify the name and path of the output file which will be appended with “.ooc” for the index file and “_node” for the data directory.
Log file generation: use -l to specify a log file where data about preprocessing should be written in addition to stdout.
Maximum memory usage: use -m to specify the maximum amount of memory in MB that will be used in preprocessing. The default is 512. Note that this is an approximate value.
Maximum shell size: use -s to specify the maximum number of points for a shell at a given node in the point cloud. The default is 10,000.
Overwrite existing files: use -r to indicate that OOC should overwrite existing files.
Culling bounding box: use -b to specify a bounding box outside of which points will be disregarded.
Subsample percentage: use -p to specify a percentage of overall points to import.
Using the programmatic approach
If you want more control over how your point clouds are imported, are running on a non-Windows platform, or you simply don’t want to use the ooc.exe preprocessor, you can preprocess your point cloud files programmatically. This is a three-step process which uses the Point Cloud API.
// Create a new point cloud, configure output, initialized with the bounding box
HPS::OOC::PointCloudOptions options(HPS::UTF8(output_file.c_str()), bbmin, bbmax);
HPS::OOC::PointCloud pointCloud(scene.GetTarget(), options);
// Add the points to the point cloud
size_t addedPoints = pointCloud.AddPoints(points, intensities, colors);
// Export the point cloud to disk
pointCloud.Export();
// Create a new point cloud, configure output, initialized with the bounding box
HPS.OOC.PointCloudOptions options = new PointCloudOptions(output_file, bbmin, bbmax);
HPS.OOC.PointCloud pointCloud = new PointCloud(scene.GetTarget(), options);
// Add the points to the point cloud
int addedPoints = pointCloud.AddPoints(points, intensities, colors);
// Export the point cloud to disk
pointCloud.Export();
Please note that despite originating in memory, these points still must be written to disk in the form of an OOC file. This process organizes the points in an optimized way so that when loaded again, they can be rendered efficiently.
Using the OOC API
HOOPS Visualize provides a set of API functions for point cloud operations. To use the point cloud API, you must include the file sprk_ooc.h. All point cloud classes are members of the OOC namespace.
This API provides:
A means to determine if a segment is an OOC root
Mappings between segments and nodes
Persistent deletion of entire nodes
Persistent deletion of specific node points
Writing out such deletions to disk and being able to read them back in
Iteration of point cloud points
OOC uses a PointCloud class to store different clouds and instances of clouds. A PointCloud object is stored in its own segment, and has one or more NodeHandle objects associated with it. As part of the preprocessor algorithm, Visualize will logically divide a point cloud into nodes. A node contains a set of spatially-related points. NodeHandle is the interface to use to interact with each node. Using NodeHandle, you can interact with individual points by performing operations such as counting and deleting.
Architecture Overview
Once an OOC file and its associated directory of node files have been preprocessed, the OOC file can be loaded into the HOOPS Visualize scene graph.
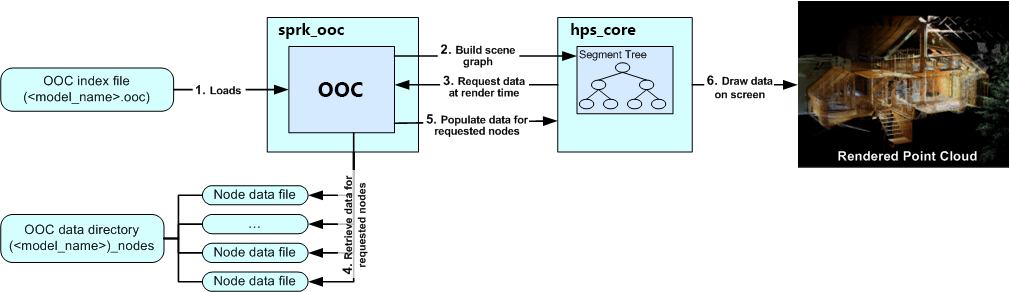
The loading and rendering of point cloud data
The following workflow describes what happens when an OOC file is loaded into HOOPS Visualize:
The OOC file is read by HOOPS Visualize.
With the information from the OOC file, the OOC Sprocket can build a scene graph in the Visualize database. This scene graph is a spatial representation of the point cloud. Each node in the tree corresponds a portion of the point cloud spatially.
At render time, Visualize traverses the segment tree. For each node, it determines if that portion of the point cloud will be drawn to the screen. If a specific area of the point cloud is visible to the camera, then Visualize will request data for that node from the OOC Sprocket.
The OOC Sprocket will then find the data file corresponding to the correct node and load it into memory. At this point, the data is put into a queue which is used for performance and memory management.
The OOC Sprocket works with Visualize to determine when node data can be loaded into the database.
Visualize draws the point cloud data on the screen.
Because the loading and storing of data in memory can be a highly intensive process, Visualize implements several mechanisms to balance the throughput of data with system performance. Visualize and the OOC Sprocket work in concert to control the amount of data loaded at any given time. Additionally, Visualize also carefully manages the amount of memory used. As parts of the model move out of the view frustum or are extent culled, Visualize depopulates the data from the associated segments. Geometry is flushed from memory. As areas become visible again, data is reloaded. Visualize uses caching logic so that in situations where the camera is panning back and forth or zooming in and out, data is not disposed of prematurely.
Please note, static models shouldn’t be used for Point Clouds, as they will more than likely hinder performance.
Importing OOC Files
OOC imports files with mechanisms similar to Visualize. As with HSF files, there are four basic steps:
Use an import options kit to set the file load options.
Load the file. Using a notifier is highly recommended, but not required. All files are loaded asynchronously.
Take appropriate action based on the status of the notifier.
Respond to any errors or exceptions.
OOC Import Example
The following example shows how to load a preprocessed OOC file into Visualize. OOC files are loaded via the File::Import method of the OOC Sprocket.
HPS::OOC::ImportNotifier notifier;
HPS::IOResult status = HPS::IOResult::Failure;
std::string message;
try {
HPS::OOC::ImportOptionsKit ioOpts;
ioOpts.SetTarget(_model);
notifier = HPS::OOC::File::Import(myPointCloudFilePath, ioOpts);
notifier.Wait();
status = notifier.Status();
_view.FitWorld();
_canvas.UpdateWithNotifier(HPS::Window::UpdateType::Exhaustive).Wait();
}
catch (HPS::IOException const& ex) {
status = ex.result;
message = ex.what();
}
HPS.OOC.ImportNotifier notifier;
HPS.IOResult status = HPS.IOResult.Failure;
string message;
try
{
HPS.OOC.ImportOptionsKit ioOpts = new HPS.OOC.ImportOptionsKit();
ioOpts.SetTarget(_model);
notifier = HPS.OOC.File.Import(myPointCloudFilePath, ioOpts);
notifier.Wait();
status = notifier.Status();
_view.FitWorld();
_canvas.UpdateWithNotifier(HPS.Window.UpdateType.Exhaustive).Wait();
}
catch (HPS.IOException ex)
{
status = ex.result;
message = ex.what();
}
OOC Operators
The OOC Sandbox app includes two operators for use with point clouds: OOCPointHighlightOperator and OOCAreaHighlightOperator. These operators work similarly to HPS::HighlightOperator and HPS::HighlightAreaOperator, but should only be used with OOC models. If you try to select non-OOC data with these operators, the functionality is undefined.
Vertex Decimation/Randomization
When working with point clouds, vertex decimation can help improve performance, and vertex randomization can help improve appearance.
Vertex decimation is a quick and direct way to tell HOOPS to only draw a percentage of the vertices in the scene; it is set using the HPS::DrawingAttributeKit::SetVertexDecimation() function. Once the vertices have been decimated, the HPS::DrawingAttributeKit::SetVertexRandomization function will cause vertices that are compiled into display lists to be inserted in random order. Vertex randomization provides a more uniform point distribution when applying vertex decimation to non-randomized data.
Please note, vertex decimation does not decrease the number of vertices loaded into memory - it only instructs HOOPS Visualize to draw fewer of them.
Here’s how to set vertex decimation/randomization on a segment:
SegmentKey mySegment = _canvas.GetFrontView().GetSegmentKey();
mySegment.GetDrawingAttributeControl().SetVertexDecimation(0.05f);
mySegment.GetDrawingAttributeControl().SetVertexRandomization(true);
_canvas.Update(HPS::Window::UpdateType::Refresh);
SegmentKey mySegment = _canvas.GetFrontView().GetSegmentKey();
mySegment.GetDrawingAttributeControl().SetVertexDecimation(0.05f);
mySegment.GetDrawingAttributeControl().SetVertexRandomization(true);
_canvas.Update(HPS.Window.UpdateType.Refresh);
Filtering
Filtering is a way to create a subset of points based on criteria you specify.
Step 1: Create the Filter Class
Any class that performs filtering must derive from HPS::OOC::QueryFilter. You must override the filter’s virtual methods to create logic that will satisfy your requirements. The following is a basic filter that will accept all points; the overridden AcceptPoint function increments a new member variable containing the total number of points:
class CountAll: public OOC::QueryFilter {
public:
CountAll(size_t in_point_count = 0): point_count(in_point_count) {}
// determines whether or not points in memory are rejected by the filter
virtual bool RejectPointsInMemory() override { return false; }
// determines whether or not points *not* in memory are rejected by the filter
virtual bool RejectPointsOnDisk() override { return false; }
// determines whether or not a point cloud node is rejected by the filter
virtual bool RejectNode(OOC::NodeHandle const& /*node_handle*/) override { return false; }
// determines whether or not a bounding box of points is rejected by the filter
virtual bool RejectBounding(Point const& /*min_bound*/, Point const& /*max_bound*/) override { return false; }
// determines whether or not a single point is accepted by the filter
virtual bool AcceptPoint(Point const& /*point*/, size_t /*point_index*/) override
{
++point_count;
return true;
}
size_t point_count;
};
public class CountAll : OOC.QueryFilter
{
public CountAll()
{
point_count = 0;
}
public CountAll(ulong in_point_count = 0)
{
point_count = in_point_count;
}
// determines whether or not points in memory are rejected by the filter
public override bool RejectPointsInMemory()
{
return false;
}
// determines whether or not points *not* in memory are rejected by the filter
public override bool RejectPointsOnDisk()
{
return false;
}
// determines whether or not a point cloud node is rejected by the filter
public override bool RejectNode(OOC.NodeHandle node_handle)
{
return false;
}
// determines whether or not a bounding box of points is rejected by the filter
public override bool RejectBounding(Point min_bound, Point max_bound)
{
return false;
}
// determines whether or not a single point is accepted by the filter
public override bool AcceptPoint(Point point, ulong point_index)
{
++point_count;
return true;
}
ulong point_count;
}
OOC will execute the filter in the order the functions are listed above. The return value for each function determines whether a point or set of points are accepted or rejected. For example, if you want the filter to only accept points that are currently in memory, you would set the return value of RejectPointOnDisk to true.
The following class is functionally the same as the one above, but instead of accepting every point that comes through the filter, it only accepts every other point, resulting in a point cloud containing half as many points:
class AcceptHalf: public OOC::QueryFilter {
public:
AcceptHalf(size_t in_point_count = 0): point_count(in_point_count) {}
// determines whether or not a single point is accepted by the filter
virtual bool AcceptPoint(Point const& point, size_t point_index) override
{
if (point_index % 2 == 0) {
++point_count;
return true;
}
else
return false;
}
size_t point_count;
};
public class AcceptHalf : OOC.QueryFilter {
public AcceptHalf()
{
point_count = 0;
}
public AcceptHalf(ulong in_point_count = 0)
{
point_count = in_point_count;
}
// determines whether or not a single point is accepted by the filter
public override bool AcceptPoint(Point point, ulong point_index)
{
if (point_index % 2 == 0)
{
++point_count;
return true;
}
else return false;
}
ulong point_count;
}
Step 2: Execute the Filter
After the filter is created, it must be instantiated and subsequently executed by calling HPS::OOC::PointCloud::QueryPoints(). Note that this function returns an iterator to the set of points that meet the filter’s criteria. This first sample executes a query using the filter that accepts all of the points (i.e., nothing is getting filtered).
size_t num_points = 0;
OOC::PointCloud point_cloud(_model);
if (point_cloud.Empty()) {
// the point cloud model is empty
}
CountAll filter;
OOC::QueryIterator it = point_cloud.QueryPoints(filter);
while (true) {
HPS::OOC::QueryIterator::Status status = it.GetStatus();
if (status != HPS::OOC::QueryIterator::Status::Alive) {
break; // No more points to iterate or there was a problem.
}
++num_points;
it.Next();
}
ulong num_points = 0;
OOC.PointCloud point_cloud = new OOC.PointCloud(_model);
if (point_cloud.Empty())
{
// the point cloud model is empty
}
CountAll filter = new CountAll();
OOC.QueryIterator it = point_cloud.QueryPoints(filter);
while (true)
{
HPS.OOC.QueryIterator.Status status = it.GetStatus();
if (status != HPS.OOC.QueryIterator.Status.Alive)
{
break; // No more points to iterate or there was a problem.
}
++num_points;
it.Next();
}
The num_points local variable is a counter against which you can verify the counter from your filter class, but it doesn’t serve any functional purpose. Finally, this sample executes a query using the filter that only accepts every other point, resulting in a point cloud containing roughly half as many points as the unfiltered point cloud:
size_t num_points_half = 0;
AcceptHalf filter_half;
OOC::QueryIterator it_half = point_cloud.QueryPoints(filter_half);
while (true) {
HPS::OOC::QueryIterator::Status status = it_half.GetStatus();
if (status != HPS::OOC::QueryIterator::Status::Alive) {
break; // No more points to iterate or there was a problem.
}
++num_points_half;
it_half.Next();
}
ulong num_points_half = 0;
AcceptHalf filter_half = new AcceptHalf();
OOC.QueryIterator it_half = point_cloud.QueryPoints(filter_half);
while (true)
{
HPS.OOC.QueryIterator.Status status = it_half.GetStatus();
if (status != HPS.OOC.QueryIterator.Status.Alive)
{
break; // No more points to iterate or there was a problem.
}
++num_points_half;
it_half.Next();
}
Sample Code
Included in the installation is an MFC C++ OOC Sandbox app. This app will load .ooc files, and includes the HighlightOperator and the AreaHighlightOperator operators which interact with point cloud data.
