HOOPS AI - Minimal ETL Demo
This notebook demonstrates the core features of the HOOPS AI data-engineering workflows.
This demo uses a small subset of the CADSynth dataset, with 101 files prepared for this tutorial. See the citation cell below for the required dataset reference.
Key Components
Schema-Based Dataset Organization: Define structured data schemas for consistent data merging
Parallel Task Decorators: Simplify CAD processing with type-safe task definitions
Generic Flow Orchestration: Automatically handle task dependencies and data flow
Automatic Dataset Merging: Process multiple files into a unified dataset structure
Integrated Exploration Tools: Analyze and prepare data for ML workflows
The framework automatically generates visualization assets and stream-cache data to support downstream applications.
CADSynth Dataset Citation
This notebook uses a 101-file subset derived from the CADSynth dataset for demonstration purposes.
Required citation Zhang, Shuming (2024). CADSynth: A Dataset for Machining Feature Recognition in B-rep Models. V1. Science Data Bank. https://doi.org/10.57760/sciencedb.17011
Dataset page https://www.scidb.cn/en/detail?dataSetId=931c088fd44f4d3e82891a5180f10d90
Subset note The local tutorial folder packages/cadfiles/cadsynth100/step is a small sample prepared for this ETL demo. It is not the full CADSynth release.
[1]:
from scripts.helper_tutorials import load_environement_variables
load_environement_variables()
[2]:
import hoops_ai
import os
import sys
license_key = os.environ.get("HOOPS_AI_LICENSE")
if not license_key:
sys.exit("HOOPS_AI_LICENSE environment variable is required.")
hoops_ai.set_license(license_key, validate=True)
------------------------------------------------------------
HOOPS AI
------------------------------------------------------------
Platform : Linux 6.17.0-29-generic
Architecture : x86_64
Python : 3.12.3
------------------------------------------------------------
Core : hoops-ai 1.1.0
CAD Access : hoops-exchange 26.2.0.dev7 (build: 1e11169 2026-03-23T17:47:19Z)
Conversion : hoops-converter 26.1.0.dev8 (build: 876a4c1 2026-05-25T07:03:01Z)
Insights : hoops-web-viewer 26.1.0.dev6 (build: 111330c 2026-05-26T11:15:51Z)
------------------------------------------------------------
======================================================================
[OK] HOOPS AI License: Valid
======================================================================
Import Dependencies
The HOOPS AI framework provides several key modules:
flowmanager: Core orchestration engine with task decoratorscadaccess: CAD file loading and model access utilitiesstorage: Data persistence and retrieval componentsdataset: Tools for exploring and preparing merged datasets
[3]:
import os
import pathlib
from typing import Tuple, List
# Import the flow builder framework from the library
import hoops_ai
from hoops_ai.flowmanager import flowtask
from hoops_ai.cadaccess import HOOPSLoader, HOOPSTools
from hoops_ai.cadencoder import BrepEncoder
from hoops_ai.dataset import DatasetExplorer
from hoops_ai.storage import DataStorage, CADFileRetriever, LocalStorageProvider
from hoops_ai.storage.datasetstorage.schema_builder import SchemaBuilder
Configuration Setup
Define input and output paths for CAD processing:
Input directory containing source CAD files
Output directory for processed results
Source directory with a small CADSynth subset used by this demo
The framework will automatically organize outputs into structured directories.
[4]:
# Configuration - Using simpler paths
nb_dir = pathlib.Path.cwd()
datasources_dir = nb_dir.parent.joinpath("packages","cadfiles","cadsynth100","step")
if not datasources_dir.exists():
print("Data source directory does not exist. Please check the path.")
exit(-1)
flows_outputdir = nb_dir.joinpath("out")
flows_outputdir
[4]:
PosixPath('/home/maxime.marechal/Projects/HAI-Tutorials/notebooks/out')
Schema Definition - The Foundation of Dataset Organization
The SchemaBuilder defines a structured blueprint for how CAD data should be organized:
Domain & Version: Namespace and versioning for schema tracking
Groups: Logical data categories (e.g., “machining”, “faces”, “edges”)
Arrays: Typed data containers with defined dimensions
Metadata Routing: Rules for routing metadata to appropriate storage
Schemas ensure consistent data organization across all processed files, enabling automatic merging and exploration.
[5]:
# Schema is now defined in cad_tasks.py for ProcessPoolExecutor compatibility
# Import it from there to view or customize
from scripts.cad_tasks import cad_schema
print(cad_schema)
{'version': '1.0', 'domain': 'Manufacturing_Analysis', 'groups': {'machining': {'primary_dimension': 'part', 'arrays': {'machining_category': {'dims': ['part'], 'dtype': 'int32', 'description': 'Machining complexity category (1-5)'}, 'material_type': {'dims': ['part'], 'dtype': 'int32', 'description': 'Material type (1-5)'}, 'estimated_machining_time': {'dims': ['part'], 'dtype': 'float32', 'description': 'Estimated machining time in hours'}}, 'description': 'Manufacturing and machining classification data'}}, 'description': 'Minimal schema for manufacturing classification', 'metadata': {'metadata': {'file_level': {}, 'categorical': {'material_type_description': {'dtype': 'str', 'required': False, 'description': 'Material classification'}}, 'routing_rules': {'file_level_patterns': [], 'categorical_patterns': ['material_type_description', 'category', 'type'], 'default_numeric': 'file_level', 'default_categorical': 'categorical', 'default_string': 'categorical'}}}}
[6]:
# Import task functions from external module for ProcessPoolExecutor compatibility
from scripts.cad_tasks import gather_files, encode_manufacturing_data
[7]:
from display_utils import display_task_source
display_task_source(gather_files, "gather_files")
gather_files
@flowtask.extract(
name="gather cad files",
inputs=["cad_datasources"],
outputs=["cad_dataset"],
parallel_execution=True
)
def gather_files(source: str) -> List[str]:
# Use simple glob pattern matching for ProcessPoolExecutor compatibility
patterns = ["*.stp", "*.step", "*.iges", "*.igs"]
source_files = []
for pattern in patterns:
search_path = os.path.join(source, pattern)
files = glob.glob(search_path)
source_files.extend(files)
print(f"Found {len(source_files)} CAD files in {source}")
return source_files
[8]:
display_task_source(encode_manufacturing_data, "encode_manufacturing_data")
encode_manufacturing_data
@flowtask.transform(
name="Manufacturing data encoding",
inputs=["cad_dataset"],
outputs=["cad_files_encoded"],
parallel_execution=True
)
def encode_manufacturing_data(cad_file: str, cad_loader: HOOPSLoader, storage: DataStorage) -> str:
# Load CAD model using the process-local HOOPSLoader
cad_model = cad_loader.create_from_file(cad_file)
# Set the schema for structured data organization
# Schema is defined at module level, so it's available in all worker processes
storage.set_schema(cad_schema)
# Prepare BREP for feature extraction
hoopstools = HOOPSTools()
hoopstools.adapt_brep(cad_model, None)
# Extract geometric features using BrepEncoder
brep_encoder = BrepEncoder(cad_model.get_brep(), storage)
brep_encoder_live = BrepEncoder(cad_model.get_brep())
graph_data = brep_encoder_live.push_face_adjacency_graph()
# Topology & Graph
graph = brep_encoder.push_face_adjacency_graph()
extended_adj = brep_encoder.push_extended_adjacency()
neighbors_count = brep_encoder.push_face_neighbors_count()
edge_paths = brep_encoder.push_face_pair_edges_path(max_allow_edge_length=16)
# Geometric Indices & Attributes
face_attrs, face_types_dict = brep_encoder.push_face_attributes()
face_discretization = brep_encoder.push_face_discretization(pointsamples=100)
edge_attrs, edge_types_dict = brep_encoder.push_edge_attributes()
curve_grids = brep_encoder.push_curvegrid(ugrid=10)
# Face-Pair Histograms
distance_hists = brep_encoder.push_average_face_pair_distance_histograms(grid=10, num_bins=64)
angle_hists = brep_encoder.push_average_face_pair_angle_histograms(grid=10, num_bins=64)
# Generate manufacturing classification data
file_basename = os.path.basename(cad_file)
file_name = os.path.splitext(file_basename)[0]
# Set seed for reproducible results based on filename
random.seed(hash(file_basename) % 1000)
# Generate classification values
machining_category = random.randint(1, 5)
material_type = random.randint(1, 5)
estimated_time = random.uniform(0.5, 10.0)
# Material type descriptions
material_descriptions = ["Steel", "Aluminum", "Titanium", "Plastic", "Composite"]
# Save data using the OptStorage API (data_key format: "group/array_name")
storage.save_data("machining/machining_category", np.array([machining_category], dtype=np.int32))
storage.save_data("machining/material_type", np.array([material_type], dtype=np.int32))
storage.save_data("machining/estimated_machining_time", np.array([estimated_time], dtype=np.float32))
# Save categorical metadata (will be routed to .attribset)
storage.save_metadata("material_type_description", material_descriptions[material_type - 1])
# Save file-level metadata (will be routed to .infoset)
storage.save_metadata("Item", str(cad_file))
storage.save_metadata("Flow name", "minimal_manufacturing_flow")
# Compress the storage into a .data file
storage.compress_store()
return storage.get_file_path("")
Flow Orchestration and Automatic Dataset Generation
The hoops_ai.create_flow() function orchestrates the data flow execution. The tasks parameters can receive any function defined by the user. This is fully editable, you can write your OWN encoding logic.
[9]:
# Create and run the Data Flow
flow_name = "minimal_manufacturing_flow"
cad_flow = hoops_ai.create_flow(
name=flow_name,
tasks=[gather_files, encode_manufacturing_data], # Imported from cad_tasks.py
max_workers=12, # parallel running
flows_outputdir=str(flows_outputdir),
ml_task="Manufacturing Classification Demo",
export_visualization=True
)
# Run the flow to process all files
print("Starting flow execution with ProcessPoolExecutor...")
print("Schema is defined in cad_tasks.py, available to all worker processes")
flow_output, output_dict, flow_file = cad_flow.process(inputs={'cad_datasources': [str(datasources_dir)]})
# Display results
print("\n" + "="*70)
print("FLOW EXECUTION COMPLETED SUCCESSFULLY")
print("="*70)
print(f"\nDataset files created:")
print(f" Main dataset: {output_dict.get('flow_data', 'N/A')}")
print(f" Info dataset: {output_dict.get('flow_info', 'N/A')}")
print(f" Attributes: {output_dict.get('flow_attributes', 'N/A')}")
print(f" Flow file: {flow_file}")
print(f"\nTotal processing time: {output_dict.get('Duration [seconds]', {}).get('total', 0):.2f} seconds")
print(f"Files processed: {output_dict.get('file_count', 0)}")
Cleaning up existing flow directory: /home/maxime.marechal/Projects/HAI-Tutorials/notebooks/out/flows/minimal_manufacturing_flow
Removing all previous outputs for flow 'minimal_manufacturing_flow' to avoid build conflicts.
Starting flow execution with ProcessPoolExecutor...
Schema is defined in cad_tasks.py, available to all worker processes
Found 101 CAD files in /home/maxime.marechal/Projects/HAI-Tutorials/packages/cadfiles/cadsynth100/step
[DatasetMerger] Saved schema with 5 groups to metadata.json
Sequential Task end=====================
======================================================================
FLOW EXECUTION COMPLETED SUCCESSFULLY
======================================================================
Dataset files created:
Main dataset: /home/maxime.marechal/Projects/HAI-Tutorials/notebooks/out/flows/minimal_manufacturing_flow/minimal_manufacturing_flow.dataset
Info dataset: /home/maxime.marechal/Projects/HAI-Tutorials/notebooks/out/flows/minimal_manufacturing_flow/minimal_manufacturing_flow.infoset
Attributes: /home/maxime.marechal/Projects/HAI-Tutorials/notebooks/out/flows/minimal_manufacturing_flow/minimal_manufacturing_flow.attribset
Flow file: /home/maxime.marechal/Projects/HAI-Tutorials/notebooks/out/flows/minimal_manufacturing_flow/minimal_manufacturing_flow.flow
Total processing time: 68.07 seconds
Files processed: 101
[ ]:
DATA SERVING : Use the DatasetExplorer to navigate your data
[10]:
# Explore the generated dataset
explorer = DatasetExplorer(flow_output_file=str(flow_file))
explorer.print_table_of_contents()
[DatasetExplorer] Default local cluster started: <Client: 'tcp://127.0.0.1:33375' processes=1 threads=16, memory=7.45 GiB>
--- Dataset Table of Contents ---
EDGES_GROUP:
EDGE_CONVEXITIES_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
EDGE_DIHEDRAL_ANGLES_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
EDGE_INDICES_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
EDGE_LENGTHS_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
EDGE_TYPES_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
EDGE_U_GRIDS_DATA: Shape: (7269, 10, 6), Dims: ('edge', 'u', 'component'), Size: 436140
FILE_ID_CODE_EDGES_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
FACEFACE_GROUP:
A3_DISTANCE_DATA: Shape: (87426, 64), Dims: ('facepair', 'bin'), Size: 5595264
D2_DISTANCE_DATA: Shape: (87426, 64), Dims: ('facepair', 'bin'), Size: 5595264
EXTENDED_ADJACENCY_DATA: Shape: (87426,), Dims: ('facepair',), Size: 87426
FACE_PAIR_EDGES_PATH_DATA: Shape: (87426, 16), Dims: ('facepair', 'dim_path'), Size: 1398816
FILE_ID_CODE_FACEFACE_DATA: Shape: (87426,), Dims: ('facepair',), Size: 87426
FACES_GROUP:
FACE_AREAS_DATA: Shape: (2796,), Dims: ('face',), Size: 2796
FACE_CENTROIDS_DATA: Shape: (2796, 3), Dims: ('face', 'dim'), Size: 8388
FACE_DISCRETIZATION_DATA: Shape: (2796, 100, 7), Dims: ('face', 'sample', 'component'), Size: 1957200
FACE_INDICES_DATA: Shape: (2796,), Dims: ('face',), Size: 2796
FACE_LOOPS_DATA: Shape: (2796,), Dims: ('face',), Size: 2796
FACE_NEIGHBORSCOUNT_DATA: Shape: (2796,), Dims: ('face',), Size: 2796
FACE_TYPES_DATA: Shape: (2796,), Dims: ('face',), Size: 2796
FILE_ID_CODE_FACES_DATA: Shape: (2796,), Dims: ('face',), Size: 2796
GRAPH_GROUP:
EDGES_DESTINATION_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
EDGES_SOURCE_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
FILE_ID_CODE_GRAPH_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
NUM_NODES_DATA: Shape: (7269,), Dims: ('edge',), Size: 7269
MACHINING_GROUP:
ESTIMATED_MACHINING_TIME_DATA: Shape: (101,), Dims: ('part',), Size: 101
FILE_ID_CODE_MACHINING_DATA: Shape: (101,), Dims: ('part',), Size: 101
MACHINING_CATEGORY_DATA: Shape: (101,), Dims: ('part',), Size: 101
MATERIAL_TYPE_DATA: Shape: (101,), Dims: ('part',), Size: 101
==================================
Columns in file_info:
name id description flow_name stream_cache_png stream_cache_3d subset table_name
0 01d86f3bf21321f42d2cc44bcb32e314_0 0 ...files/cadsynth100/step/00000033.stp minimal_manufacturing_flow ...86f3bf21321f42d2cc44bcb32e314_0.png ...86f3bf21321f42d2cc44bcb32e314_0.scs N/A file_info
1 06840f88cb5c9e6a3a28d3fb326457f9_0 1 ...files/cadsynth100/step/00000047.stp minimal_manufacturing_flow ...40f88cb5c9e6a3a28d3fb326457f9_0.png ...40f88cb5c9e6a3a28d3fb326457f9_0.scs N/A file_info
2 0f52429569b5ff7d077bfc67103e7257_0 2 ...files/cadsynth100/step/00000009.stp minimal_manufacturing_flow ...2429569b5ff7d077bfc67103e7257_0.png ...2429569b5ff7d077bfc67103e7257_0.scs N/A file_info
3 1050d723613b9fd920151d93ed4f48bd_0 3 ...files/cadsynth100/step/00000062.stp minimal_manufacturing_flow ...0d723613b9fd920151d93ed4f48bd_0.png ...0d723613b9fd920151d93ed4f48bd_0.scs N/A file_info
4 180f86463f78cbc05e70b2950ee303b9_0 4 ...files/cadsynth100/step/00000071.stp minimal_manufacturing_flow ...f86463f78cbc05e70b2950ee303b9_0.png ...f86463f78cbc05e70b2950ee303b9_0.scs N/A file_info
5 1a05d8050504c2b9c6da8312d4e3e5d4_0 5 ...files/cadsynth100/step/00000088.stp minimal_manufacturing_flow ...5d8050504c2b9c6da8312d4e3e5d4_0.png ...5d8050504c2b9c6da8312d4e3e5d4_0.scs N/A file_info
6 1a2b10980a28582e5965b6a8cec8e872_0 6 ...files/cadsynth100/step/00000086.stp minimal_manufacturing_flow ...b10980a28582e5965b6a8cec8e872_0.png ...b10980a28582e5965b6a8cec8e872_0.scs N/A file_info
7 20308062f57b849b64c1062c5523e193_0 7 ...files/cadsynth100/step/00000044.stp minimal_manufacturing_flow ...08062f57b849b64c1062c5523e193_0.png ...08062f57b849b64c1062c5523e193_0.scs N/A file_info
8 20a46419d850c21d9c6296d7936c7692_0 8 ...files/cadsynth100/step/00000091.stp minimal_manufacturing_flow ...46419d850c21d9c6296d7936c7692_0.png ...46419d850c21d9c6296d7936c7692_0.scs N/A file_info
9 20c9c68abe34339bd18e06af53007b8d_0 9 ...files/cadsynth100/step/00000013.stp minimal_manufacturing_flow ...9c68abe34339bd18e06af53007b8d_0.png ...9c68abe34339bd18e06af53007b8d_0.scs N/A file_info
.. ... ... ... ... ... ... ... ...
91 e2d53daaea40c6fd1eab5ed890ec7209_0 91 ...files/cadsynth100/step/00000048.stp minimal_manufacturing_flow ...53daaea40c6fd1eab5ed890ec7209_0.png ...53daaea40c6fd1eab5ed890ec7209_0.scs N/A file_info
92 e51ad31ceca4363af2a4d45ae53d97c2_0 92 ...files/cadsynth100/step/00000035.stp minimal_manufacturing_flow ...ad31ceca4363af2a4d45ae53d97c2_0.png ...ad31ceca4363af2a4d45ae53d97c2_0.scs N/A file_info
93 e5b04d42236397e85d9519ee836066b3_0 93 ...files/cadsynth100/step/00000059.stp minimal_manufacturing_flow ...04d42236397e85d9519ee836066b3_0.png ...04d42236397e85d9519ee836066b3_0.scs N/A file_info
94 ecbf1f2809a8f8572daeda22716a966b_0 94 ...files/cadsynth100/step/00000024.stp minimal_manufacturing_flow ...f1f2809a8f8572daeda22716a966b_0.png ...f1f2809a8f8572daeda22716a966b_0.scs N/A file_info
95 f281eefd616724cdda1861993a03784e_0 95 ...files/cadsynth100/step/00000015.stp minimal_manufacturing_flow ...1eefd616724cdda1861993a03784e_0.png ...1eefd616724cdda1861993a03784e_0.scs N/A file_info
96 f54b17f82fc258408013c1613f498bcd_0 96 ...files/cadsynth100/step/00000058.stp minimal_manufacturing_flow ...b17f82fc258408013c1613f498bcd_0.png ...b17f82fc258408013c1613f498bcd_0.scs N/A file_info
97 f6666617a75d4fcd3a77f295c3ac08c3_0 97 ...files/cadsynth100/step/00000060.stp minimal_manufacturing_flow ...66617a75d4fcd3a77f295c3ac08c3_0.png ...66617a75d4fcd3a77f295c3ac08c3_0.scs N/A file_info
98 f8f654f17a0de27c13ccc0e79d11bbca_0 98 ...files/cadsynth100/step/00000099.stp minimal_manufacturing_flow ...654f17a0de27c13ccc0e79d11bbca_0.png ...654f17a0de27c13ccc0e79d11bbca_0.scs N/A file_info
99 fa29d49ebe22666724f6cc1ab50a880d_0 99 ...files/cadsynth100/step/00000028.stp minimal_manufacturing_flow ...9d49ebe22666724f6cc1ab50a880d_0.png ...9d49ebe22666724f6cc1ab50a880d_0.scs N/A file_info
100 ff72723692b897708e73da849b944f09_0 100 ...files/cadsynth100/step/00000034.stp minimal_manufacturing_flow ...2723692b897708e73da849b944f09_0.png ...2723692b897708e73da849b944f09_0.scs N/A file_info
ML-Ready Dataset Preparation
The DatasetLoader provides tools for preparing the merged dataset for machine learning:
Key Capabilities:
Stratified Splitting: Create train/validation/test splits while preserving class distributions
Subset Tracking: Records file assignments in the dataset metadata
[11]:
# Load and split dataset for machine learning
from hoops_ai.dataset import DatasetLoader
flow_path = pathlib.Path(flow_file)
loader = DatasetLoader(
merged_store_path=str(flow_path.parent / f"{flow_path.stem}.dataset"),
parquet_file_path=str(flow_path.parent / f"{flow_path.stem}.infoset")
)
# Split dataset by machining category with explicit group parameter
train_size, val_size, test_size = loader.split(
key="machining_category",
group="machining", # Explicitly specify the group for clarity
train=0.6,
validation=0.2,
test=0.2,
random_state=42
)
print(f"Dataset split: Train={train_size}, Validation={val_size}, Test={test_size}")
# Access training dataset
train_dataset = loader.get_dataset("train")
print(f"Training dataset ready with {len(train_dataset)} samples")
loader.close_resources()
[DatasetExplorer] Default local cluster started: <Client: 'tcp://127.0.0.1:33133' processes=1 threads=16, memory=7.45 GiB>
WARNING: 101/101 graph .pt files are missing on disk. split() will work (uses infoset metadata), but item loading will fail for those entries. Run the graph encoding step to generate the missing .pt files before calling get_dataset().
DEBUG: Successfully built file lists with 101 files out of 101 original file codes
============================================================
DATASET STRUCTURE OVERVIEW
============================================================
Group: edges
------------------------------
edge_convexities: (7269,) (int32)
edge_dihedral_angles: (7269,) (float32)
edge_indices: (7269,) (int32)
edge_lengths: (7269,) (float32)
edge_types: (7269,) (int32)
edge_u_grids: (7269, 10, 6) (float32)
file_id_code_edges: (7269,) (int64)
Group: faceface
------------------------------
a3_distance: (87426, 64) (float32)
d2_distance: (87426, 64) (float32)
extended_adjacency: (87426,) (float32)
face_pair_edges_path: (87426, 16) (int32)
file_id_code_faceface: (87426,) (int64)
Group: faces
------------------------------
face_areas: (2796,) (float32)
face_centroids: (2796, 3) (float32)
face_discretization: (2796, 100, 7) (float32)
face_indices: (2796,) (int32)
face_loops: (2796,) (int32)
face_neighborscount: (2796,) (int32)
face_types: (2796,) (int32)
file_id_code_faces: (2796,) (int64)
Group: graph
------------------------------
edges_destination: (7269,) (int32)
edges_source: (7269,) (int32)
file_id_code_graph: (7269,) (int64)
num_nodes: (7269,) (int32)
Group: machining
------------------------------
estimated_machining_time: (101,) (float32)
file_id_code_machining: (101,) (int64)
machining_category: (101,) (int32)
material_type: (101,) (int32)
============================================================
Dataset split by machining_category: Train=60, Validation=19, Test=22
Dataset split: Train=60, Validation=19, Test=22
Training dataset ready with 60 samples
[DatasetExplorer] Shutting down this Dask client...
[DatasetExplorer] Closing the LocalCluster...
[DatasetExplorer] All resources closed.
[DatasetExplorer] All resources closed.
Summary: The HOOPS AI - Data Flow Advantage
This minimal example demonstrates how HOOPS AI simplifies CAD data processing for ML:
Schema-First Approach: Define your data structure before processing
Decorator-Based Tasks: Easily inject custom processing logic
Automatic Orchestration: Let the framework handle execution complexity
Unified Dataset: Get consistently merged data ready for ML
Built-in Exploration: Analyze and prepare datasets with powerful tools
The framework automatically generates visualization assets and stream caches, making it easy to integrate with downstream visualization tools.
[12]:
# Visualization libraries
import matplotlib.pyplot as plt
def print_distribution_info(dist, title="Distribution"):
"""Helper function to print and visualize distribution data."""
list_filecount = list()
for i, bin_files in enumerate(dist['file_id_codes_in_bins']):
list_filecount.append(bin_files.size)
dist['file_count'] =list_filecount
# Visualization with matplotlib
fig, ax = plt.subplots(figsize=(12, 4))
bin_centers = 0.5 * (dist['bin_edges'][1:] + dist['bin_edges'][:-1])
ax.bar(bin_centers, dist['file_count'], width=(dist['bin_edges'][1] - dist['bin_edges'][0]),
alpha=0.7, color='steelblue', edgecolor='black', linewidth=1)
# Add file count annotations
for i, count in enumerate(dist['file_count']):
if count > 0: # Only annotate non-empty bins
ax.text(bin_centers[i], count + 0.5, f"{count}",
ha='center', va='bottom', fontsize=8)
ax.set_xlabel('Value')
ax.set_ylabel('Count')
ax.set_title(f'{title} Histogram')
ax.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
[13]:
import time
start_time = time.time()
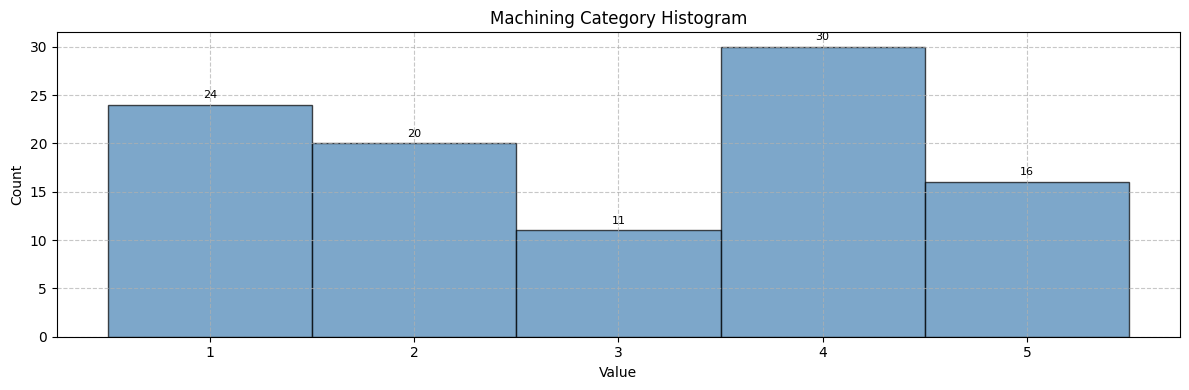
face_dist = explorer.create_distribution(key="machining_category", bins=None, group="machining")
print(f"Machining distribution created in {(time.time() - start_time):.2f} seconds\n")
print_distribution_info(face_dist, title="Machining Category")
Machining distribution created in 0.21 seconds
Dataset Visualization with DatasetViewer
The DatasetViewer is a powerful visualization tool that bridges dataset queries and visual analysis. It enables you to quickly visualize query results in two ways:
Image Grids: Generate collages of PNG previews for rapid visual scanning
Interactive 3D Views: Open inline 3D viewers for detailed model inspection
[14]:
# Import the DatasetViewer from the insights module
from hoops_ai.insights import DatasetViewer
# Create a DatasetViewer using the convenience method from_explorer
# This method queries the explorer and builds the file ID to visualization path mappings
dataset_viewer = DatasetViewer.from_explorer(explorer)
[ ]:
[15]:
start_time = time.time()
# condition
material_is_frequent = lambda ds: ds['material_type'] == 2
filelist = explorer.get_file_list(group="machining", where=material_is_frequent)
print(f"Filtering completed in {(time.time() - start_time):.2f} seconds")
print(filelist)
Filtering completed in 0.03 seconds
[ 0 1 14 15 19 26 28 30 32 33 43 45 46 53 57 60 64 65 71 78 79 85 92 99]
[ ]:
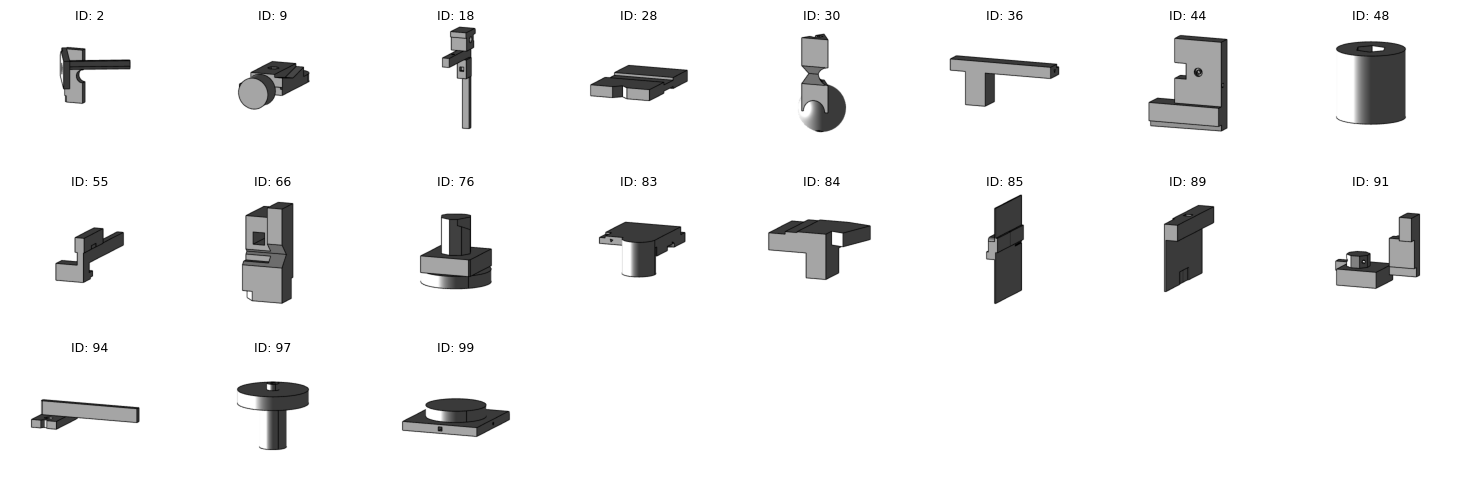
Example 1: Visualize Query Results as Image Grid
Now let’s use the query results we obtained earlier and visualize them as a grid of images. This is perfect for quickly scanning through many files to understand patterns or identify specific cases.
[16]:
# Visualize the filtered files as a 5x5 grid with file IDs as labels
fig = dataset_viewer.show_preview_as_image(
filelist,
k=len(filelist), # Show up to 25 files
grid_cols=4, # 5 columns
label_format='id', # Show file IDs as labels
figsize=(15, 5) # Larger figure size
)
plt.show()