Preprocessing Data
HOOPS/OOC provides a simple command line executable for processing your data. It is called ooc.exe and can be found in the bin directory of the HOOPS installation.
When the preprocessor receives a point cloud file, it performs three passes of the data. In each pass, every single data point is examined. As a result, this stage can take a significant amount of time. We suggest that you allow for sufficient preprocessing time prior to loading and rendering your model.
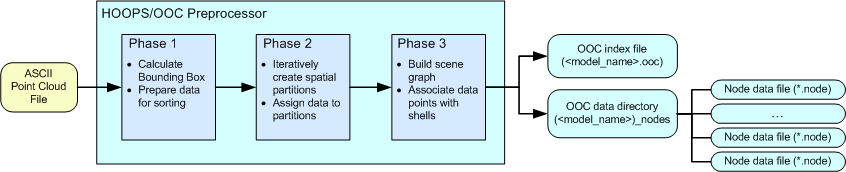
The three phases of preprocessing
The following list describes the three phases of input data preprocessing:
- HOOPS/OOC loads in all the data points and calculates a bounding box that contains the entire data set. One or more temporary binary files are created to house the data for rapid access in subsequent phases.
- HOOPS/OOC reads the temporary binary files and then spatially sorts the points. If a user-specified bounding box was defined, HOOPS/OOC will exclude any points outside of this volume. Additionally, users can specify a subsample percentage that tells HOOPS/OOC to sort only a portion of the points in the dataset. HOOPS/OOC uses a version of the binary space partition algorithm to sort the data. For each partition, it creates a node that stores a user-specifiable number of points. This number will be the size of the shell that later is loaded into the HOOPS database. If the number of data points exceeds the limit, then HOOPS/OOC subdivides the node further until the threshold is not surpassed. While sorting the points, HOOPS/OOC adheres to a memory limit. If the memory usage reaches the limit, HOOPS/OOC writes the least recently used nodes out to disk to free up memory so that it can continue processing the remaining data.
- After the data has been spatially sorted, HOOPS/OOC organizes the points into an appropriate scene graph so that HOOPS can render the data efficiently. Beginning at the root node, HOOPS/OOC creates a shell and assigns a randomized user-specified number of points to it. As HOOPS/OOC moves down the tree, the child nodes are representations of the partitions created in phase two. Each child node is populated with a percentage of the data corresponding to the fraction of data that resides in its respective partitioned area. HOOPS/OOC moves recursively until the leaves of the tree are reached and there are no more partitions. This tree structure is written to an OOC file (*
.ooc*) while the data that belongs to each node is written into a node file (*.node*). Node files live in a directory with the same root name and at the same level as the OOC file.
There are two different ways that a point cloud data file can be processed. You can use the OOC preprocessor or you can use a programmatic approach. Each method is described below.
Using the ooc.exe preprocessor
The ooc.exe program is a Windows application that will consume a raw point cloud data file (.ptx, .pts, etc.) and produce a file that HOOPS Visualize is able to consume.
To preprocess a point cloud file, run ooc.exe from the command line. This program takes a number of options - but the most important is the input file name, which is passed with the -f option. The following example shows how you might preprocess the MyPointCloud.ptx ASCII point cloud file:
> ooc -f ../data/MyPointCloud.ptx -l ../data/MyPointCloudLog.txt
The above command line entry tells ooc.exe to process the ../data/MyPointCloud.ptx file. In the data directory, it creates a MyPointCloudLog_ptx.ooc file along with a MyPointCloudLog_ptx_nodes directory that contains a series of .node data files. Additionally, it will also create a MyPointCloudLog.txt log file. The preprocessor takes a number of options that lets you control how your data is analyzed and organized. They are as follows:
- Input filename: use -f to specify the name and path of the ASCII point cloud file. To specify multiple input files, provide multiple -f filename arguments to the preprocessor or give a -F filename with a file containing a list of point cloud files (one per line).
- Output filename: use -o to specify the name and path of the output file which will be appended with “.ooc” for the index file and “_node” for the data directory.
- Log file generation: use -l to specify a log file where data about preprocessing should be written in addition to stdout.
- Maximum memory usage: use -m to specify the maximum amount of memory in MB that will be used in preprocessing. The default is 512. Note that this is an approximate value.
- Maximum shell size: use -s to specify the maximum number of points for a shell at a given node in the point cloud. The default is 10,000.
- Overwrite existing files: use -r to indicating that HOOPS/OOC should overwrite existing files.
- Culling bounding box: use -b to specify a bounding box outside of which points will be disregarded.
- Subsample percentage: use -p to specify a percentage of overall points to import.
Using the programmatic approach
If you want more control over how your point clouds are imported, are running on a non-Windows platform, or you simply don’t want to use the ooc.exe preprocessor, you can preprocess your point cloud files programmatically. This is a three-step process which uses the Point Cloud API.
- Configure the preprocessor object:
OOC::Preprocessor preprocessor(output_ooc_filename);
Instead of using command-line arguments as described in the previous subsection, those settings are exposed as API function calls. For example:
preprocessor.SetMaxShellSize(max_size);
preprocessor.OverwriteExistingFiles(true);
preprocessor.SetMaxMemoryUsage(max_memory);
preprocessor.SetCullingBoundingBox(culling_min, culling_max);
IMPORTANT: The OOC preprocessor will automatically calculate the bounding box. However, when using the programmatic approach, you are expected to calculate the minimum and maximum values and configure the preprocessor using SetCullingBoundingBox. Failure to do so may result in undefined behavior.
Lastly, Initialize is called:
preprocessor.Initialize();
The sets the file that will be imported as well as prepares the preprocessor to work.
- Add your points to the HOOPS Visualize database. This involves calling one of the two
AddPointsfunctions.AddPointscan be called as many times as necessary to get all of your points into the database.
size_t AddPoints(size_t count,
float const* points,
float const* intensities = nullptr,
unsigned char const* colors = nullptr);
- Once all points have been imported, calling
Export()will cause HOOPS to create the OOC files. The result of this step is the .ooc file which can then be consumed by HOOPS Visualize.
preprocessor.Export();
Sample code snippet demonstrating this process:
OOC::Preprocessor preprocessor(point_cloud_filename);
preprocessor.SetCullingBoundingBox(culling_min, culling_max);
preprocessor.Initialize();
float p[3];
fp = fopen(input_file_name.c_str(), "r");
while (get_point(fp, p)) {
preprocessor.AddPoints(1, p);
}
fclose(fp);
preprocessor.Export();

