Multi-Threaded Performance Critical Applications
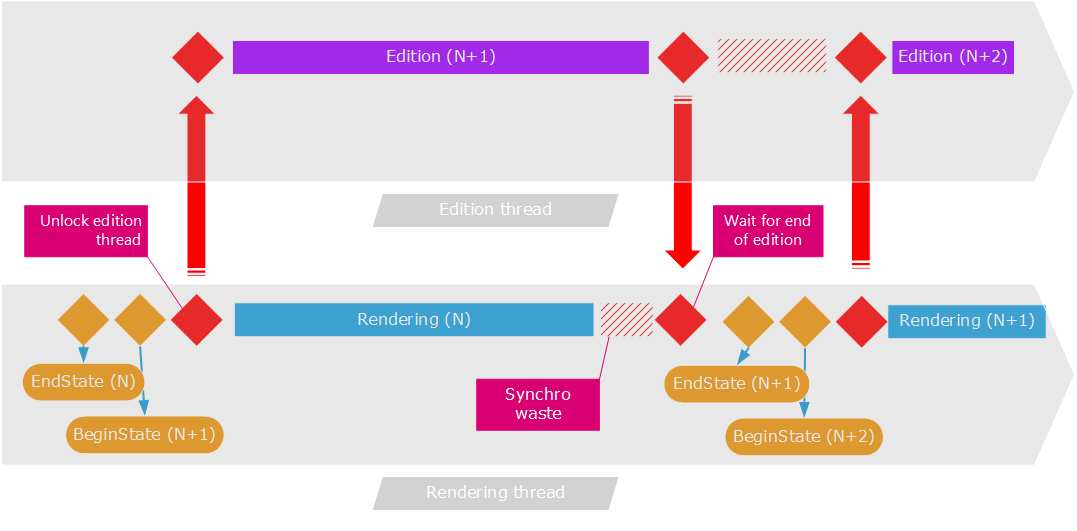
The rendering workflow of a time critical rendering application
The basic principle depicted in the schema above is all about using one thread for the edition purposes inside HOOPS Luminate and another thread (generally the main application thread) for rendering purposes.
In HOOPS Luminate, only one single thread can be used to do changes in the engine data. The application must choose which one will edit HOOPS Luminate contents, and proceed with all changes from that unique thread. If this rule is not enforced, the engine may crash. Transaction management calls (RED::IResourceManager::BeginState and RED::IResourceManager::EndState) must occur from the rendering thread.
In HOOPS Luminate, any thread can query engine data (therefore using R/O access methods that are NOT using transactions).
From this, the goal of this architecture is to match the edition time with the rendering time. If both tasks do take roughly the same time to complete, then the application has achieved a near optimal performance. We can see on the schema that the rendering thread is displaying the transaction number N while the edition thread is calculating the transaction N+1.
There can be two source of performance drops from this architecture:
- There are unequal rendering and edition times: the longer task will be the performance bottleneck.
RED::IResourceManager::EndStatetakes a long time to complete. While this is rarely significative, big changes in the manipulated data can cause the engine to take some time to update.
The red arrows in the schema depict a simple blocking / unblocking synchronization between the edition thread and the rendering thread. Edition must be blocked until the next transaction is started. The rendering thread must be blocked after draw while the edition thread has not finished; before the transaction can be closed.
Image Management
As detailed here: Modifying Images During a Draw, images are partly stateless objects. The pixel array of an image has no copy inside HOOPS Luminate and therefore can’t be managed using transactions to secure concurrent accesses to it. For the architecture depicted above, this imply that image management operations (such as uploading image pixels on the GPU) must be done from the rendering thread, after the end of the edition, before the transaction end:
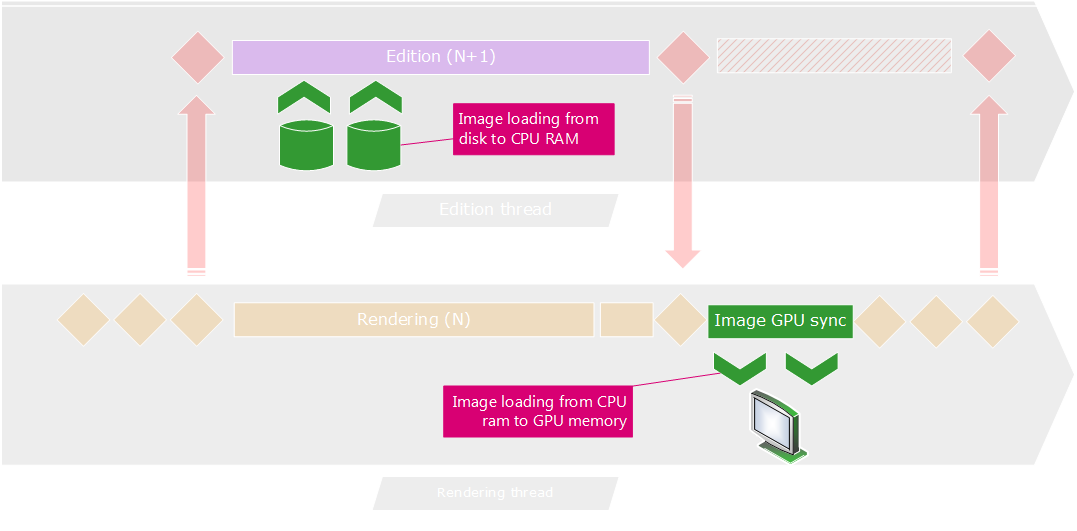
Image management workflow in a multi-threaded application model.
Loading images from the disk to the CPU ram occur on the edition thread. If .red files are used to perform image loading operations, the RED::StreamingPolicy::SetLocalImages must be enabled. This ensure that no GPU operation will interfere with the rendering thread during the load operation from the edition thread. If this policy is not enabled, then the OpenGL layer of the GPU rendering will have to manage concurrent calls from two threads. This will result in small sudden, random, performance drops.
One images are loaded into the CPU RAM, they can be quickly uploaded from the GPU. In the illustration above, we describe one possible solution, using a synchronization point right after the edition has finished, before the RED::IResourceManager::EndState call. All RED::IImage2D::SetPixels operations are synchronous. The speed of uploading data to the GPU is expressed in 10’s of Gigabytes, so textures can be uploaded each frame at a very satisfying rate for the application.
Hardware Latency and Frame Buffer Synchronization
It’s very unlikely that you can measure the time spent in each thread of such an architecture without ensuring a proper synchronization of the frame buffer first. In this architecture, no call is ever blocking the application, making any analysis attempt a nightmare:
- OpenGL calls do NOT block the application. At the end of a frame, HOOPS Luminate does a
::SwapBufferscall to switch the front and back buffer of the rendering window. This call does neither flush the OpenGL command stream nor it actually does the buffer swapping immediately. Depending on the OpenGL driver implementation on the hardware being used and run operating system, the behavior can differ. Generally speaking OpenGL drivers developed by hardware vendors do use multi-threading optimizations to speed up the rendering and introduce several frames of latency before displaying anything. This can be really annoying if very large datasets are to be displayed, and this reduce the responsiveness of the application controls.- HOOPS Luminate does not block either. It sends all graphic orders and returns to the calling application.
So no one waits for anyone here, and good luck to you if you try to measure anything in this mess!
To overcome this and make the application behavior easier to understand, HOOPS Luminate delivers a RED::OPTIONS_WINDOW_DRAW_SYNC option. Activating this option will force everyone to calm down a bit and wait at the end of a frame for this frame to be effectively displayed by the graphic hardware. Once this option is turned on, time measurements can be made in an accurate way: the time spent rendering the complete frame will be revealed by the time spent in RED::IWindow::FrameDrawing by HOOPS Luminate.

