A Parallel Application Architecture
On large scenes that have to render in true real-time at 60 Hz minimum, data edition time may be problematic as it can interfere with the application’s rendering time and borrow some useful milliseconds.
Hopefully, modern graphics have no synchronization point, and therefore, a rendering continue after the rendering calls have returned. Let’s explain this looking at the picture below. This starts from the application architecture described here: Single-Threaded Graphic Applications:
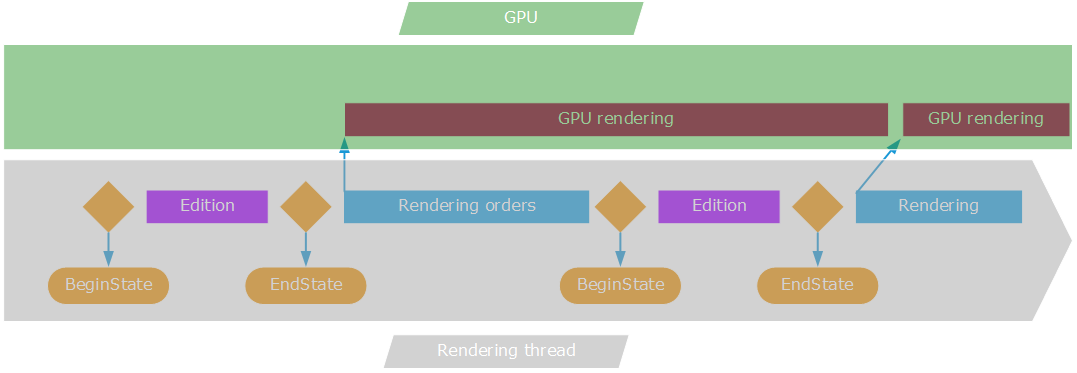
Rendering orders emitted from the rendering thread may last longer than expected
Practically speaking, if the RED::OPTIONS_WINDOW_DRAW_SYNC option is turned off, the OpenGL driver of the GPU may decide to interleave frames and to allow the application to continue working before the rendering is finished. So, in a sense, this is exactly what we want: the GPU is occupied 100% of the time, and the rendering calls will not block the application. So if there were one single rendering call to draw the entire scene, we would reach a 100% optimal parallelism with all the time of the rendering thread that could be dedicated to doing application stuff.
But real applications do have a quite complex rendering pipeline: several scene rendering passes are needed, and intermediate synchronization points are needed too, as we need intermediate images during the course of our rendering pipeline. If we zoom on the rendering orders and GPU rendering task, we’ll see that we can be fairly limited in parallelism.
Let’s consider a simple application rendering an island with a water surface showing planar reflections. To make it as simple as possible, let’s consider the following easy rendering pipeline:
- Render the reflected scene (using simplified meshes and shading)
- Render the sun shadow map
- Render the scene. The water surface uses the reflected scene image, and all meshes are using the shadow map

A simple island rendering pipeline
If you’re an old HOOPS Luminate customer, you will recognize this veeeery old tutorial ;-) So, if we zoom on the rendering call of the application, we’ll see the following sub-tasks:
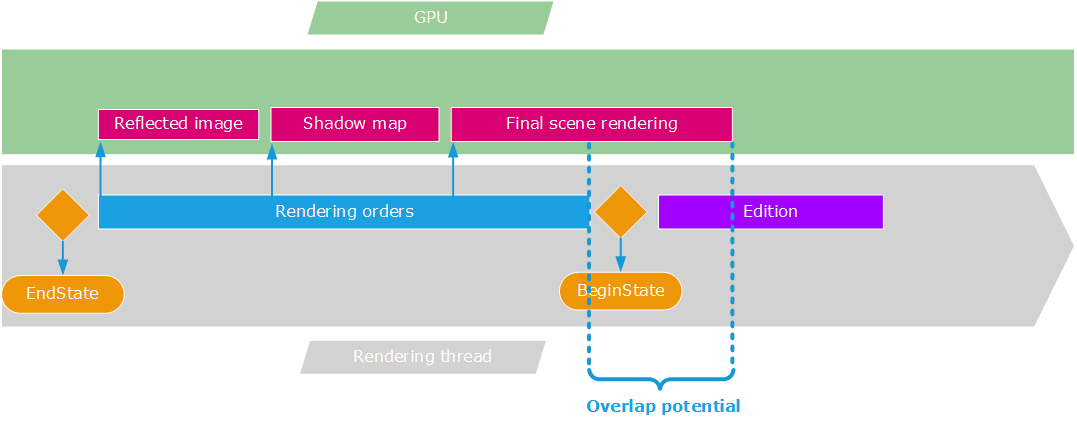
The possible overlap if we have several ongoing sub-passes during our draw
As our final pass requires results from intermediate passes, we won’t step out of RED::IWindow::FrameDrawing before having emitted all rendering orders for our full rendering pipeline. Therefore the amount of parallelism we can get will be limited to the time taken by our last rendering pass. In many modern rendering pipelines, this last pass is NOT the expensive one. This is generally a post effect pass (glow, DOF, vignetting, sharpen filter, tone-mapping, etc…), so we have only little space to take advantage of the hardware parallelism, if we remain using the single threaded graphic application model.
That’s why we also detail another rendering model here: Multi-Threaded Performance Critical Applications. This rendering model works well for critical applications that manage a lot of data and that have lots of calculations to perform on these data each frame.

